![[Performance JMeter] Bài 6 - Post Processors Extractor](/uploads/course/performance_testing_with_jmeter_and_grafana_monitor.png)
NỘI DUNG BÀI HỌC
✅ Khái niệm JSON
✅ Jsonpath
✅ Json Extractor
✅ Ví dụ minh họa
✅ Best practices
✅ Cấu trúc cơ bản của Regex
✅ Regular Expression Extractor
✅ Ví dụ minh họa
✅ Cấu trúc Boundary Extractor
✅ Ví dụ minh họa
Phần 1: JSON Extractor
1. JSON là gì?
JSON (JavaScript Object Notation) là một dạng lưu trữ và trao đổi dữ liệu rất gọn nhẹ.
-
Người dùng có thể dễ dàng đọc và viết JSON.
-
Máy tính cũng dễ dàng xử lý và tạo ra JSON.
JSON được xây dựng dựa trên hai dạng chính:
-
Cặp khóa/giá trị: Trong nhiều ngôn ngữ lập trình, thể hiện như object, dictionary, hash table hoặc key-value list.
-
Danh sách có thứ tự: Thể hiện như array, list, vector, sequence.
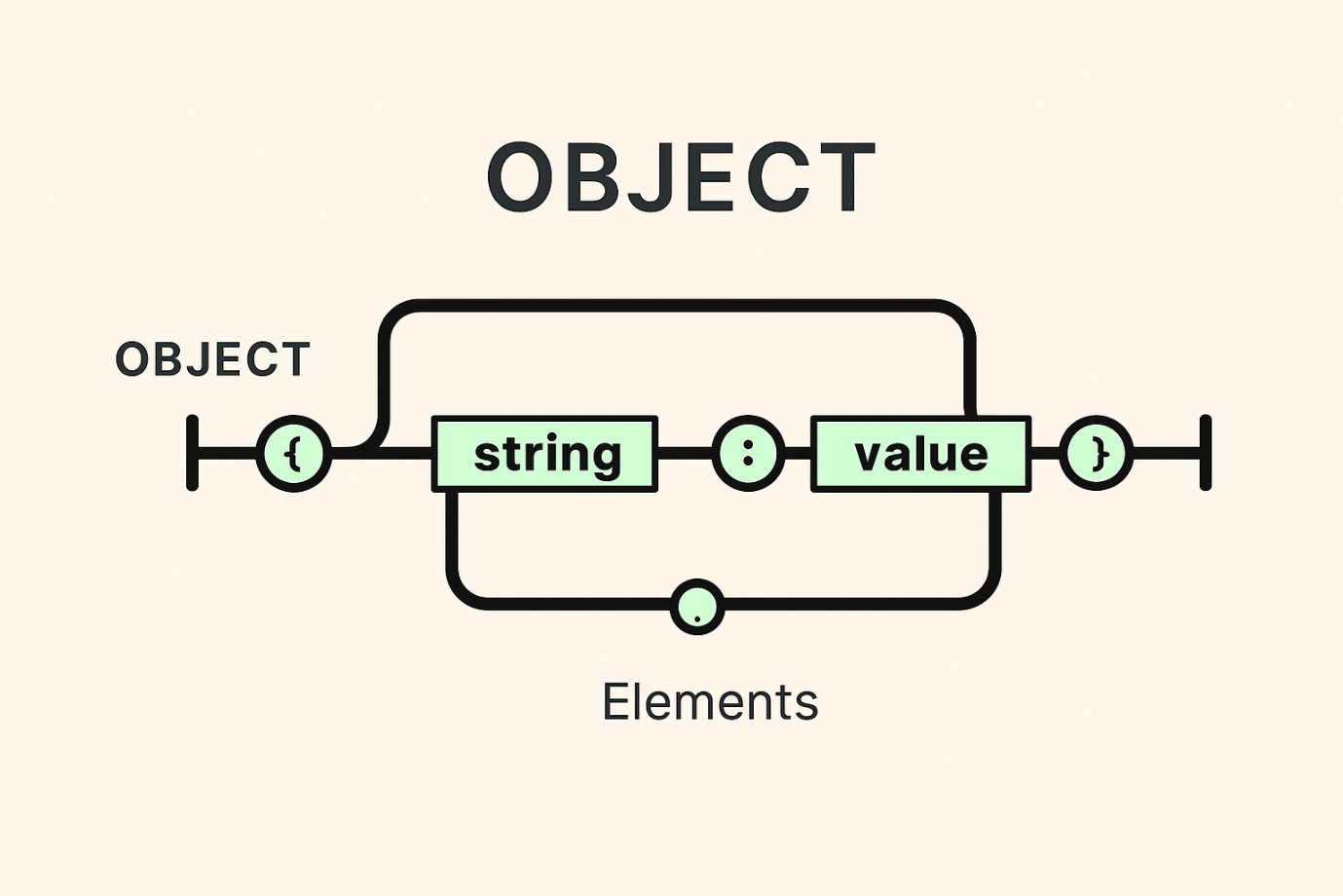
✳️Cấu trúc JSON: Object
-
Object là một tập hợp các cặp khóa – giá trị (name/value pairs), không theo thứ tự cố định.
-
Bắt đầu bằng
{và kết thúc bằng}. -
Mỗi tên đi kèm một giá trị, nối với nhau bằng dấu
:. -
Các cặp phân tách bằng dấu
,.
👉 Nói ngắn gọn: Object giống như một bảng thông tin gồm nhiều thuộc tính (tên) và giá trị tương ứng.
Ví dụ:
{ "name": "Tom", "age": 30, "city": "Ho Chi Minh"}
Ở đây:
- name là tên thuộc tính, "Tom" là giá trị.
- age là tên thuộc tính, 30 là giá trị.
- city là tên thuộc tính, "Ho Chi Minh" là giá trị.
2. JSONPath
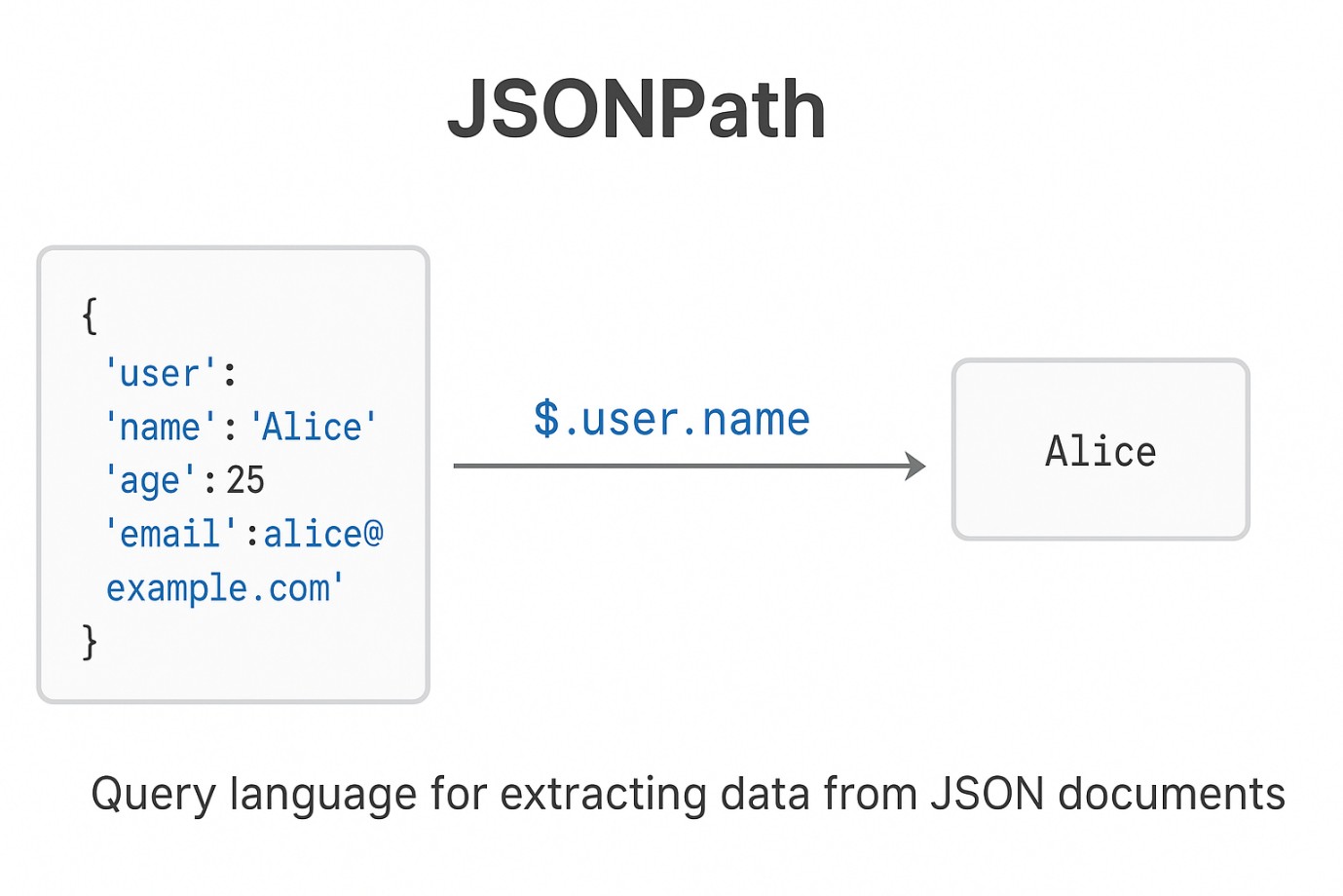
JSONPath là một ngôn ngữ truy vấn dùng để trích xuất dữ liệu từ tài liệu JSON.
-
Tương tự XPath trong XML, nhưng áp dụng cho JSON.
-
Trong JMeter, JSON Extractor sử dụng JSONPath để lấy dữ liệu từ response.
🔆Cú pháp cơ bản
| Cú pháp | Ý nghĩa | Ví dụ |
|---|---|---|
$ |
Root (gốc JSON) | $.order.id |
. |
Truy cập thuộc tính con | $.user.name |
[*] |
Chọn tất cả phần tử mảng | $.users[*].id |
[n] |
Phần tử thứ n (0-based) | $.users[0].name |
[-1] |
Phần tử cuối | $.users[-1].name |
.. |
Tìm ở mọi cấp | $..price |
?() |
Biểu thức lọc | $.products[?(@.price>1000)] |
@ |
Đối tượng hiện tại | $.products[?(@.name=="iPhone 15")] |
3. JSON Extractor
JSON Extractor dùng để trích xuất dữ liệu từ response JSON (REST API).
Vị trí thêm: (Sampler) → Add → Post Processors → JSON Extractor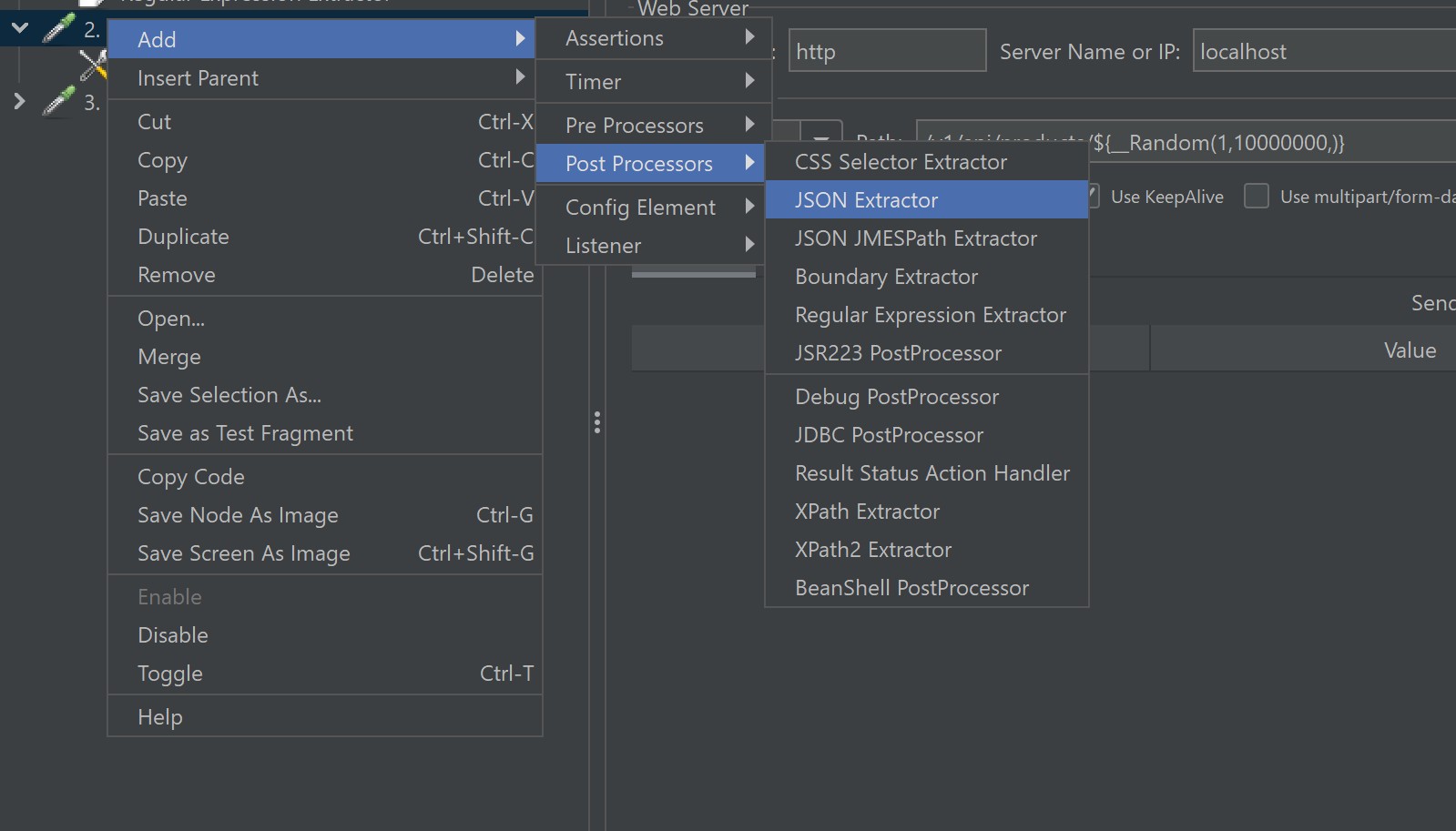
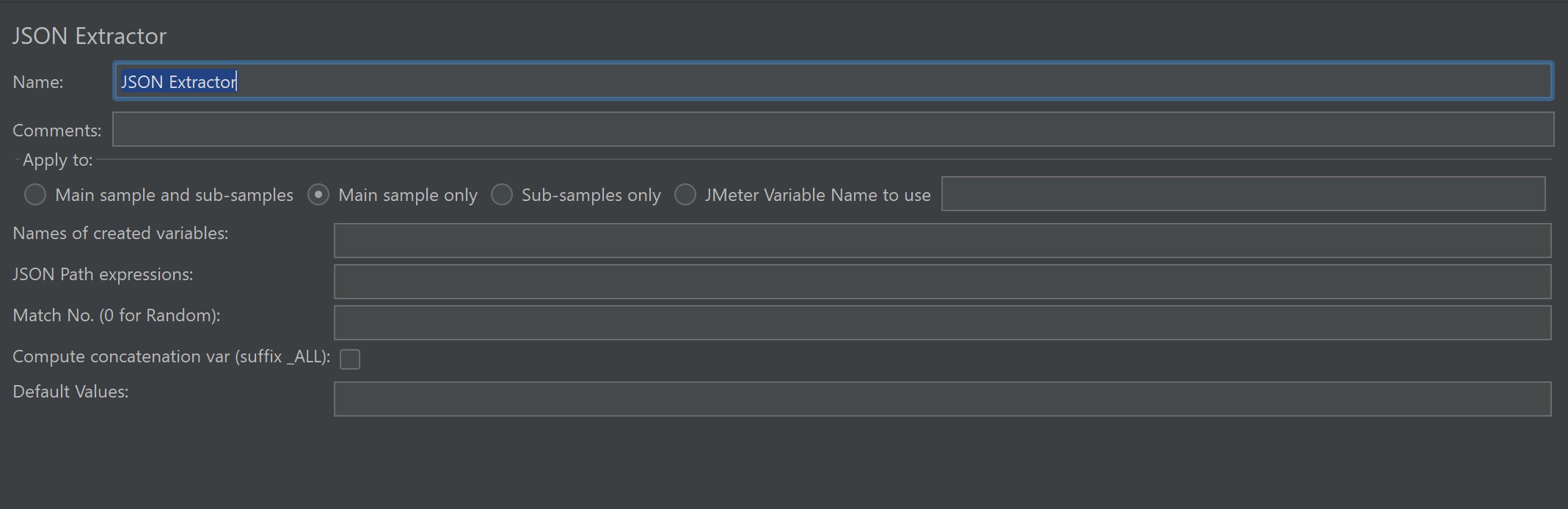
✳️Các trường cấu hình quan trọng
-
Name of created variable(s): Tên biến kết quả (ví dụ:
authToken, hoặc nhiều biến cách nhau;). -
JSON Path expressions: Biểu thức JSONPath, 1–1 với tên biến.
-
Match No.:
-
1, 2, 3…→ lấy giá trị thứ n (index từ 1). -
-1→ lấy tất cả kết quả →${var_1},${var_2}, …,${var_matchNr}. -
0→ lấy ngẫu nhiên một kết quả.
-
-
Default Values: Giá trị mặc định nếu không tìm thấy.
-
Compute concatenation var (tuỳ phiên bản): Ghép tất cả kết quả bằng dấu
,hoặc ký tự khác.
👉 Biến sinh ra khi Match Numbers = -1: ${var_1}, ${var_2}, … và ${var_matchNr} (tổng số match).
4. Ví dụ minh họa
a. Lấy giá trị đơn
Response:
{
"status": "success",
"user": { "id": 12345, "name": "Nguyen Van A", "token": "abc123xyz" }
}
- Var: authToken
- JSONPath: $.user.token
- Match No.: 1 → ${authToken} = abc123xyz
b. Lấy phần tử trong mảng
Response:
{ "users": [ {"id":101}, {"id":102}, {"id":103} ] }
- Var: uid
- JSONPath: $.users[*].id
- Match No.: -1
→ ${uid_1}=101, ${uid_2}=102, ${uid_3}=103, ${uid_matchNr}=3
c. Wildcard / Deep-scan
Response:
{"a": {"id": 1}, "b": {"id": 2}, "c": {"x": {"id": 3}}}
- JSONPath: $..id (deep-scan mọi cấp)
→ 1, 2, 3 (với -1)
d. Lọc theo điều kiện
Response:
{ "products": [
{"id":1, "name":"iPhone 15", "price":2500},
{"id":2, "name":"Samsung S24", "price":1800},
{"id":3, "name":"Xiaomi 14", "price":900}
]}
- Lấy id theo name:JSONPath: $.products[?(@.name=='Samsung S24')].id → 2
- Lấy name price > 1000:
$.products[?(@.price>1000)].name → ["iPhone 15","Samsung S24"]
Lưu ý: Filter trả một mảng. Dùng -1 để nhận từng phần tử ${var_1}, ${var_2}…
e. Nhiều biến – nhiều biểu thức
Response:
{
"order": {
"id": "ORD12345",
"date": "2025-08-26",
"customer": { "name": "Nguyen Van A", "email": "vana@example.com", "address": { "city": "Hanoi", "zip": "100000" } },
"items": [
{ "sku": "IP15", "name": "iPhone 15", "qty": 1, "price": 2500 },
{ "sku": "S24", "name": "Samsung S24", "qty": 2, "price": 1800 }
],
"status": "PAID"
}
}
- Name of variables: orderId;customerName;city
- JSONPath expressions: $.order.id;$.order.customer.name;$.order.customer.address.city
- Default Values: NA;NA;NA
f. Khóa động (dynamic keys)
Response:
{ "meta": { "v2025-08": {"build": 776, "status":"ok"} } }
- Khi khoá con biến đổi theo phiên bản, dùng deep-scan:
JSONPath: $..build → 776
g. Lấy mảng lồng nhau
Response:
{ "order": { "items": [
{"sku":"A1","batches":[{"lot":"L1"},{"lot":"L2"}]},
{"sku":"B2","batches":[{"lot":"L3"}]}
]}}
- JSONPath: $.order.items[*].batches[*].lot
→ ${lot_1}=L1, ${lot_2}=L2, ${lot_3}=L3
h. Chuỗi JSON trong JSON (2 bước)
Response:
{ "data": "{\"token\":\"ABC123\"}" }
- B1 JSON Extractor lấy chuỗi: $.data → ${raw}
- B2 JSON Extractor (áp trên Sample Variables → JMeter Variables):
- Variable names: token
- JSONPath: $.token
- JMeter Variable Name to use: raw (tuỳ cách bạn tổ chức; hoặc dùng JSR223 để parse)
i. Lọc nâng cao
Lấy id của sản phẩm có price > 900 và name là Samsung S24
- → $.products[?(@.price > 900 && @.name == "Samsung S24")].id
k. Xử lý không tồn tại (graceful)
- Set Default Value rõ ràng (NOT_FOUND), tránh rỗng gây lỗi tham chiếu ở bước sau.
- Kết hợp Response Assertion để fail sớm nếu token không được trả về.
5. Best Practices
- Dùng $..field để tìm ở mọi cấp, nhưng cẩn trọng số lượng match.
- Luôn cấu hình Default Values khi phát triển kịch bản.
- Giữ JSONPath ngắn & ổn định, hạn chế phụ thuộc thứ tự nếu API có thể đổi.
Phần 2: Regular Expression Extractor
1. Regex là gì?
Regex (Regular Expression): Cú pháp đặc biệt dùng để tìm kiếm, so khớp và xử lý chuỗi văn bản.
Ứng dụng:
-
Kiểm tra dữ liệu nhập (validation).
-
Tìm kiếm nâng cao.
-
Thay thế chuỗi.
-
Trích xuất dữ liệu từ log/file.
2. Cấu trúc cơ bản của Regex
🔹 Ký tự thường
Khớp chính xác ký tự.
Ví dụ: abc khớp với "abc".
🔹 Metacharacters (ký tự đặc biệt)
| Ký hiệu | Ý nghĩa | Ví dụ |
|---|---|---|
. |
Bất kỳ ký tự nào | a.c khớp "abc", "a1c" |
^ |
Bắt đầu chuỗi | ^Hello khớp "Hello world" |
$ |
Kết thúc chuỗi | world$ khớp "Hello world" |
* |
Lặp lại 0 hoặc nhiều lần | ab* khớp "a", "abbb" |
+ |
Lặp lại 1 hoặc nhiều lần | ab+ khớp "ab", "abbb" |
? |
0 hoặc 1 lần | colou?r khớp "color", "colour" |
{n} |
Lặp đúng n lần | \d{3} khớp "123" |
{n,m} |
Lặp từ n đến m lần | a{2,4} khớp "aa", "aaa", "aaaa" |
[] |
Một ký tự trong tập | [abc] khớp "a", "b", "c" |
() |
Nhóm | (abc)+ khớp "abcabc" |
| |
OR (hoặc) | cat|dog khớp "cat" hoặc "dog" |
🔹 Nhóm ký tự viết tắt
| Ký hiệu | Ý nghĩa | Ví dụ |
|---|---|---|
\d |
Chữ số (0-9) | \d\d → "12" |
\w |
Ký tự chữ/số/_ | \w+ → "abc123" |
\s |
Khoảng trắng | \s → " " hoặc \t |
\D |
Không phải số | \D → "a" |
\W |
Không phải ký tự chữ/số | \W → "!" |
\S |
Không phải khoảng trắng | \S → "a" |
3. Regular Expression Extractor
a. Khái niệm
-
Regular Expression Extractor là một Post-Processor trong JMeter.
-
Chức năng: trích xuất dữ liệu từ response (HTML, JSON, XML, text…) dựa vào biểu thức Regex.
-
Dữ liệu trích xuất sẽ được lưu vào biến để dùng cho các request tiếp theo.
👉 Thêm bằng cách:Right click → Add → Post Processors → Regular Expression Extractor.
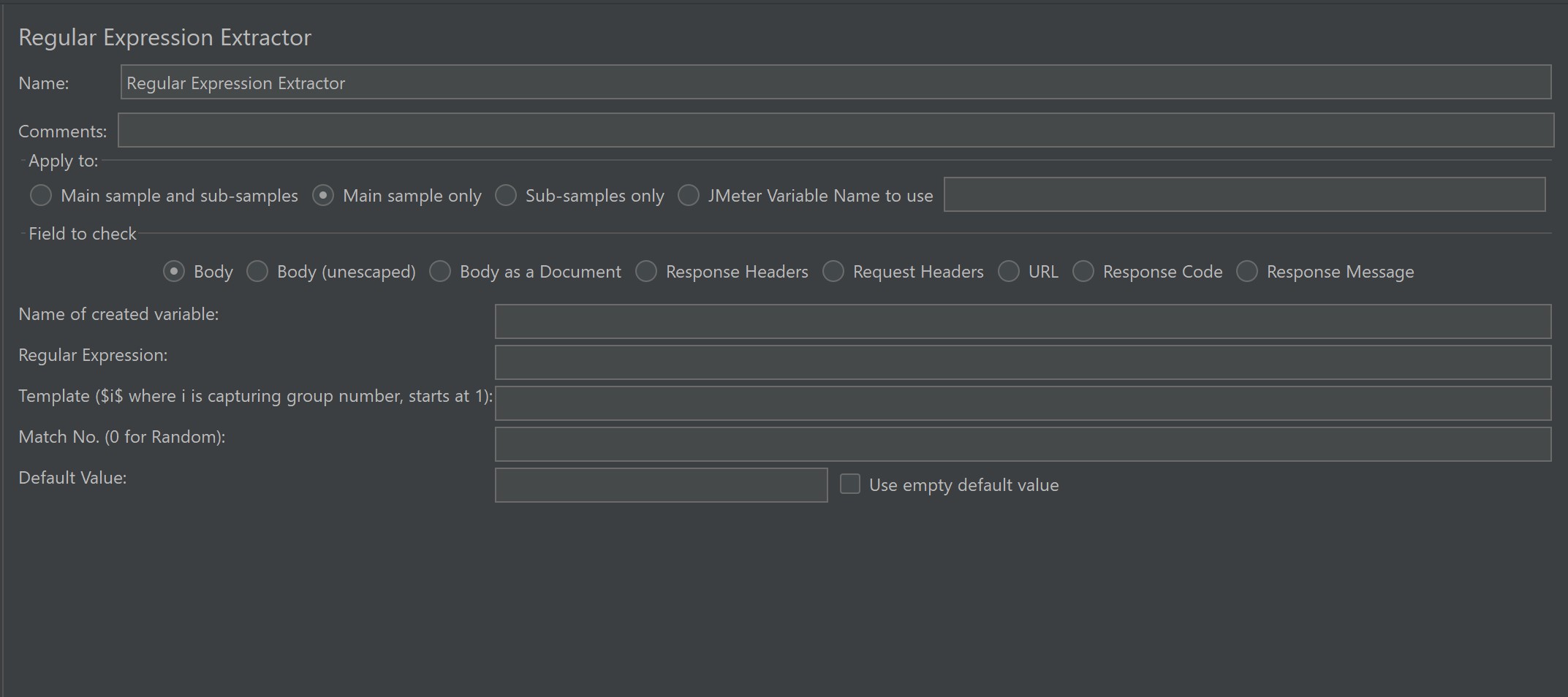
b. Các trường cấu hình chính
| Trường | Ý nghĩa |
|---|---|
| Name | Tên của Extractor (tùy chọn). |
| Apply to | Áp dụng cho: Main sample, Sub-samples, Both… |
| Field to check | Chọn nội dung cần so khớp: Response Body, Headers, URL, Response Code, Response Message. |
| Reference Name | Tên biến lưu giá trị trích xuất (ví dụ: sessionId). |
| Regular Expression | Biểu thức Regex để trích xuất. |
| Template | Chỉ định group nào trong regex được lưu, thường là $1$. |
| Match No. | Chọn kết quả: 1 = kết quả đầu tiên, -1 = tất cả. |
| Default Value | Giá trị mặc định nếu không tìm thấy kết quả. |
4. Ví dụ
Câu 1 – JSON Response
Response:
Cần trích xuất: token
Regex nào đúng?
-
A.
"token": "(.*?)" -
B.
"username": "(.*?)" -
C.
"token":\s*"(.*?)"✅ -
D.
"id": (\d+)
👉 Đáp án: C (vì xử lý được khoảng trắng).
Câu 2 – HTML Response
Response:
Cần trích xuất: 12345
Regex nào đúng?
-
A.
href="(.*?)" -
B.
/profile/(\d+)✅ -
C.
<h1>(.*?)</h1> -
D.
\d+
👉 Đáp án: B (match chính xác số trong URL).
Câu 3 – XML Response
Response:
Cần trích xuất: TXN5566778899
Regex nào đúng?
-
A.
<id>(.*?)</id>✅ -
B.
<amount>(.*?)</amount> -
C.
status>(.*?)< -
D.
<id>\d+</id>
👉 Đáp án: A.
Câu 4 – Header Response
Header:
Cần trích xuất: qwerty123abc
Regex nào đúng?
-
A.
SESSIONID=(.*?);✅ -
B.
Set-Cookie: (.*?) -
C.
Path=(.*?) -
D.
SESSIONID=(.*)
👉 Đáp án: A.
Câu 5 – Body Text
Response:
Cần trích xuất: ORD2025001
Regex nào đúng?
-
A.
#(.*?)\. -
B.
ORD\d+ -
C.
order ID is #(.*?)\. -
D.
#ORD(\d+)✅
👉 Đáp án: D (match ORD + số, loại bỏ ký tự #).
5. Kết luận & Bài tập thêm
-
Regular Expression Extractor là công cụ quan trọng trong JMeter để xử lý dữ liệu động.
-
Nên luyện tập với nhiều loại response: JSON, HTML, XML, Header, Body text.
-
Thực hành với
Match No. = -1để lấy nhiều giá trị cùng lúc.
Phần 3: Boundary Extractor
1. Giới thiệu
-
Boundary Extractor là một Post-Processor trong Apache JMeter.
-
Dùng để trích xuất dữ liệu từ Response bằng cách chỉ định:
-
Left Boundary (LB) = chuỗi đứng trước giá trị cần lấy.
-
Right Boundary (RB) = chuỗi đứng sau giá trị cần lấy.
-
-
Cách hoạt động: giống như hàm
SUBSTRING→ lấy phần nằm giữa LB và RB.
👉 Ưu điểm: dễ dùng, nhanh hơn Regex Extractor, đặc biệt khi dữ liệu có cấu trúc rõ ràng.
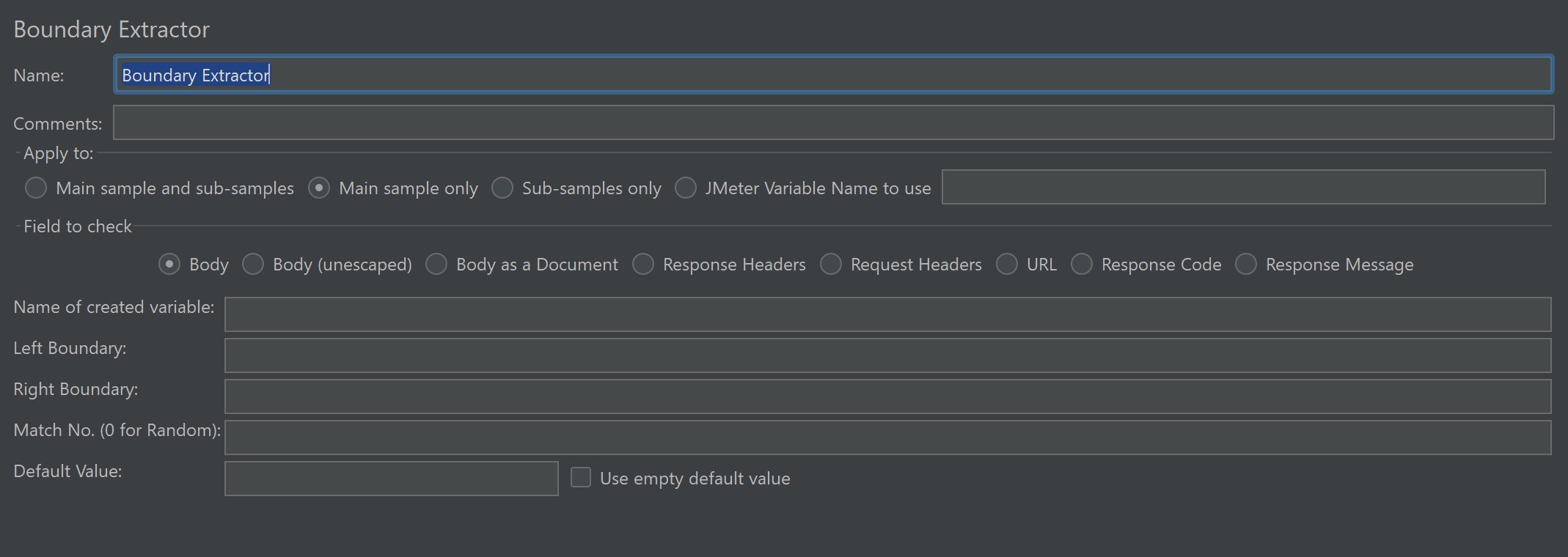
2. Cấu hình chính
- Left Boundary (LB): Chuỗi bắt đầu trước dữ liệu cần lấy.
- Right Boundary (RB): Chuỗi kết thúc sau dữ liệu cần lấy.
- Match No.: Chỉ định lấy kết quả thứ mấy (1 = đầu tiên, -1 = tất cả).
- Default Value: Giá trị trả về nếu không tìm thấy.
3. Ví dụ thực tế nâng cao
Ví dụ 1: Trích xuất token từ JSON
Response:
-
LB =
"token": " -
RB =
", -
✅ Kết quả =
abc123xyz456
Ví dụ 2: Trích xuất nhiều Cookie từ Response Header
Response Header:
-
LB =
Set-Cookie: SESSIONID=| RB =;→xyz987 -
LB =
Set-Cookie: PREF=lang=| RB =;→en
Ví dụ 3: Trích xuất dữ liệu từ HTML
-
LB =
value="| RB ="→token987xyz -
LB =
uid=| RB ="→5566
Ví dụ 4: Trích xuất dữ liệu từ XML
-
LB =
<ID>| RB =</ID>| Match No. = 1 →U12345 -
LB =
<ID>| RB =</ID>| Match No. = 2 →U67890 -
Match No. = -1 → lấy cả hai giá trị.
4. Câu hỏi trắc nghiệm
Câu 1: Với PREF=lang=en để lấy en thì cấu hình nào đúng?
✅ LB = "PREF=lang=" | RB = ";"
Câu 2: Nếu muốn lấy tất cả <ID> trong XML thì Match No. = ?
✅ -1
Câu 3: Nếu LB hoặc RB không tồn tại thì Boundary Extractor trả về gì?
✅ Default Value
5. Kết luận
Boundary Extractor hữu ích trong trường hợp dữ liệu có cấu trúc rõ ràng với LB và RB xác định.
Regex Extractor linh hoạt hơn cho dữ liệu phức tạp, nhưng Boundary Extractor dễ dùng và nhanh hơn trong nhiều trường hợp.
